Software Engineering and Machine Learning Projects
Stock Price Trajectory Classification Independent Research:
Sept 2015. - June 2016
This research focused on generating a unique stock price forecasting model through machine learning using fundamental data that is publically available to all types of investors. Unlike hedge funds, who have exclusive access to premier and costly training data acquired through financial service providers, the common investor only has access to basic public information including price, volume, and options data. Using public data as a feature set, this research studies the effectiveness of training 5 machine learning models using w days of financial history to predict how a stock’s price will rise or fall k days away within a certain target radius r.
The study primarily analyzed 3 stocks – Apple, Disney, and Nike, for their market scale and diversified representation of different sectors of the global market. Using numerous experimental methods, analysis, and thorough customized software modules programmed in Python, the model described above was successfully formulated. Moreover, the precision score accuracies for the experimental parameters (w, k, r) were optimized for the Support Vector Machine (SVM) model.
Since the framework of this research was based in Python, and as a result the “scikit-learn”, “pandas” and “numpy” were used in conjunction to implement five different ML algorithms: Logistic Regression, Naïve-Bayes Gaussian, K Neighbors Classifiers, the Decision Tree Classifier, and the Support Vector Machine (SVM). Since this research deals with a binary classification problem into the classes {1, -1}, for upward or downward movement, all five of these algorithms were trained based on the model detailed above. Each model’s performance was then evaluated on a corresponding testing data set, where the results were quantified with a precision score in the range of 0 to 1 that demonstrated the accuracy of classifying particular examples correctly. The study’s raw data was primarily aggregated from a number of Wharton databases, which was heavily preprocessed, normalized, and consolidated for specific features that needed such wrangling to achieve more sensible results.
In the end, demonstrated that an optimized SVM classifier using my model can correctly predict a stock’s directional movement on the initial collection (Apple, Disney, and Nike), as well as on a bundle of 50 stocks with ~72% accuracy on average. Concluded that there are clear correlations between historical financial data that can be used to predict a stock’s directional movement, but there is not enough confidence in these results to actually rely on such a model to manage one’s own investments, without using significantly richer training data to increase accuracy and reduce noise in the results.
Technologies Used: Python, ML Methods, Classification, Big Data Aggregation, Stock and Financial Theory, Statistics
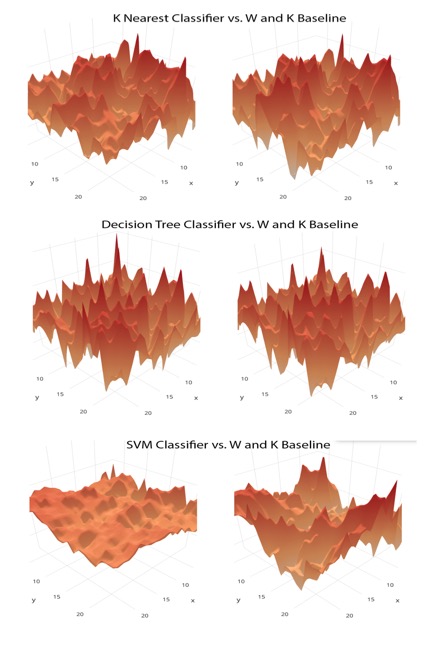
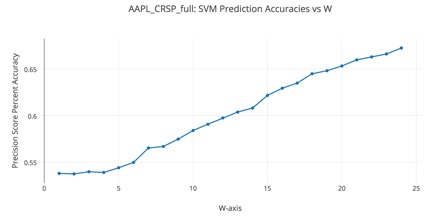
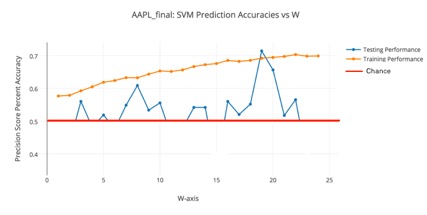
The figures shown above examine Apple. The top most figure shows 3D surface plots, parameterized against (w, k), with the z-axis depicting precision score accuracies for the top three most effective classifiers. The second figure details Apple’s un-optimized SVM training performance, while the third figure demonstrates the optimized SVM testing performance. Here, there are limited higher accuracies, albeit the effect of noise on the results is more prevalent with some overfitting through using GridSearch in the optimization and the lack of higher resolution data.

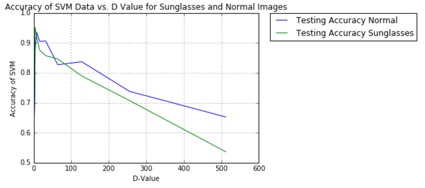
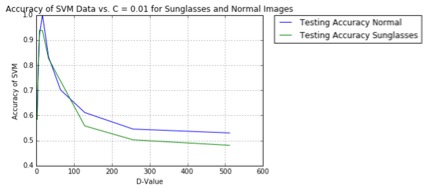
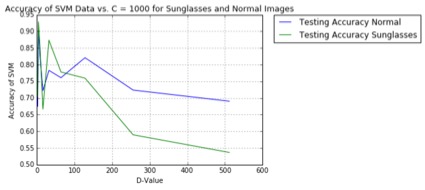
The top figure shows the images included in the Yale B dataset as a whole. The second and third images detail the varying performance between classifying four men and four women’s faces worth of data aggregated together, with and without sunglasses. The second image shows the training data with testing validation performing well, but in figure three when the eyes of each person are blocked, the testing performance drops significantly. This makes sense because eyes contain much unique information about one’s face. Lastly, figures four and five show how a varying “C” factor for an SVM can actually improve the accuracy of the classifier moving from small C’s to high C’s in this case. This is just one of many examples of SVM optimization incorporated in this project.
Facial Recognition Image Processing:
Feb - May 2016
This project aims to analyze the YALE B facial dataset to understand how well a Support Vector Machine (SVM) can classify facial images. Within this dataset, there are frontal face images of 38 participants, with roughly 60 images per subject, where the total number of images is 2,414. Since the dimensions of each image is 192 x 168 pixels, there are a total of 32,256 column vectors stored in a matrix per image, with a corresponding label for each of the 2,414 images.
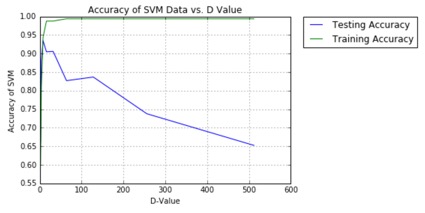
Since each image has a dimension of 32,356, it would be computationally rigorous to process these raw images. Thus, a more efficient method of principal component analysis was chosen, which involves projecting the raw image to a smaller one that keeps only “d” of the most important component vectors of the original image to preserve the most valuable information in the least space. These “d” components have the largest variances in the original image. Through such projections, the quality of the image is slightly reduced, but the gains made in computational space conservation exceed these reductions significantly.
After preprocessing the projected images and normalizing, a variety of SVM’s were constructed and tested for their training and testing performance on subsets of the data, while varying certain parameters. For example, SVM’s were tested by varying the number of “d” components used to project upon and altering the type of classifier (linear, rbf, poly, etc).
More interestingly, however, tests for binary classification on identifying men’s and women’s faces using “d” dimensional PCA projections were compared, with and without sunglasses, as shown to the left. Also, the method of implementing PCA to reduce image size was compared against simply subsampling the images. Numerous properties of SVM’s were discovered as a result of these tests, where certain kernels perform well for different tasks, while other SVM parameters like the gamma and C factors objectively increased accuracies. Further study is being conducted to determine more efficient ways to correctly classify images while further reducing the number of components used in the PCA images to improve efficiency.
Technologies Used: Python, Image Processing Theory, Support Vector Machine Optimization, Big Data Processing, Principal Component Analysis

US Patent Trade Office Marketing Automation Software
June - Aug. 2014
While interning at the Entrepreneurs Roundtable Accelerator in the summer of June – August 2014, I worked primarily with the legal startup Plainlegal to develop a marketing automation software that generated over 1 million leads to market their product. Plainlegal offers lawyers an automated method of filing trademark applications to the United States Patent Trade Office (USPTO) in the form of a compact software, which was to be advertised to all of the trademark lawyers in the United States. In order to do so, I formulated a scraping tool in Python that directly accessed the USPTO’s public directory to retrieve the background data on all of the trademark lawyers who have ever filed with the United States. There were millions of XML entries to be parsed through, where each entry had multiple aliases of lawyer data.
To make sense of the information, I crafted complex normalization and text processing methods to refine the data and store it in PostgreSQL/SQLite databases, from which data on all lawyers in the United States can be queried at ease. This information was pivotal in marketing Plainlegal’s product and led to much business and revenue generation for the company. Once the scraping routine was thoroughly tested and made robust, I pushed the code to Amazon EC2 servers in the cloud where the scripts would run continuously to add new lawyer data released by the USPTO in real time, while performing a week long cycle to collect gigabytes of historical data.
Technologies Used: Python, Amazon EC2, PostgreSQL, SQLite, XML Data Scraping and Normalization

